
Как научить OpenClaw создавать изображения
Материал для тех, у кого OpenClaw работает на моделях, у которых нет функции генерации изображений (например, Claude Sonnet, DeepSeek, Qwen).

Введение
Мы используем OpenClaw вместе с локальным Qwen и платными API DeepSeek, Claude Sonnet (в рамках наших задач это дешевле ChatGPT). Данные модели не умеют создавать изображения, поэтому у нас есть два варианта решения проблемы.
Вариант первый
Подключить модель, которая умеет работать с картинками. Тогда OpenClaw сможет автоматически использовать подходящую модель для задач, связанных с изображениями: например, для создания или анализа. Да, он сможет это делать даже если основной агент работает из-под DeepSeek: сам OpenClaw вызовет нужный инструмент, который уже под капотом определит подходящего доступного провайдера для конкретной задачи.
Второй вариант
Но что делать, если, как и в нашем случае, инструменты для работы с изображениями умеют только читать/смотреть картинки (через Claude Sonnet), но не умеют их генерировать? Всё просто: нам на помощь приходят SKILLS (навыки), которые призваны обучать агента всему, что ему может пригодиться.
Что такое SKILLS
SKILLS — это навыки, которыми обладает OpenClaw. Обычно это SKILL.md, который лежит внутри папки с навыком. Пример: /workspace/skills/${name}/SKILL.md.
То есть навык — это обычный файл, в котором по шагам, на английском языке (чтобы не тратить токены на перевод), описан процесс выполнения какого-то задания. Плюс в папке навыка могут лежать какие-то скрипты, которые OpenClaw может запускать. Зачем? Ну, например, Вы хотите обучить своего агента посылать SMS и звонить через IP-телефонию, для этого подключаете какое-то API, пишете пару скриптов на Node.js или Python и кладёте в папку с навыком. А в SKILL.md пишете путь к этим скриптам и простую документацию, как с этим работать. Ну вот и всё, агент может писать Вам SMS-сообщения и звонить на телефон.
Создаём навык для создания изображения
Мы будем создавать картинки через OpenAI API и модель gpt-image-2.
Нам не нужно покупать подписку ChatGPT, но нам нужно будет покупать токены для генерации. Нам это обходится в 5–10 долларов в месяц, только поэтому мы и используем данный подход. Суть этой статьи в том, чтобы показать, как делать сложные навыки самостоятельно. Вместо gpt-image-2 Вы можете использовать Flux или Kandinsky, особенно это полезно, если уже используете простые локальные модели. Но тогда придётся писать другой код.
Для начала Вам нужно создать рабочее окружение. Это будет Node.js + TypeScript-проект, который мы соберём через tsc и esbuild. Можете собрать всё сами как удобно, мы же покажем свою сборку.
Создаём папку, инициализируем проект через:
npm init
Устанавливаем пакеты:
npm i joi openai
И ещё:
npm i --save-dev @eslint/js @types/node esbuild eslint globals typescript typescript-eslint
В корне проекта создаём папку src, внутри — файл generateImage.useCase.ts.
И ещё, тоже в корне проекта, создаём такой путь (папка в папке): workspace/skills/image-helper.
Внутри image-helper — папку storage и файл SKILL.md. Получиться должно что-то вроде этого:
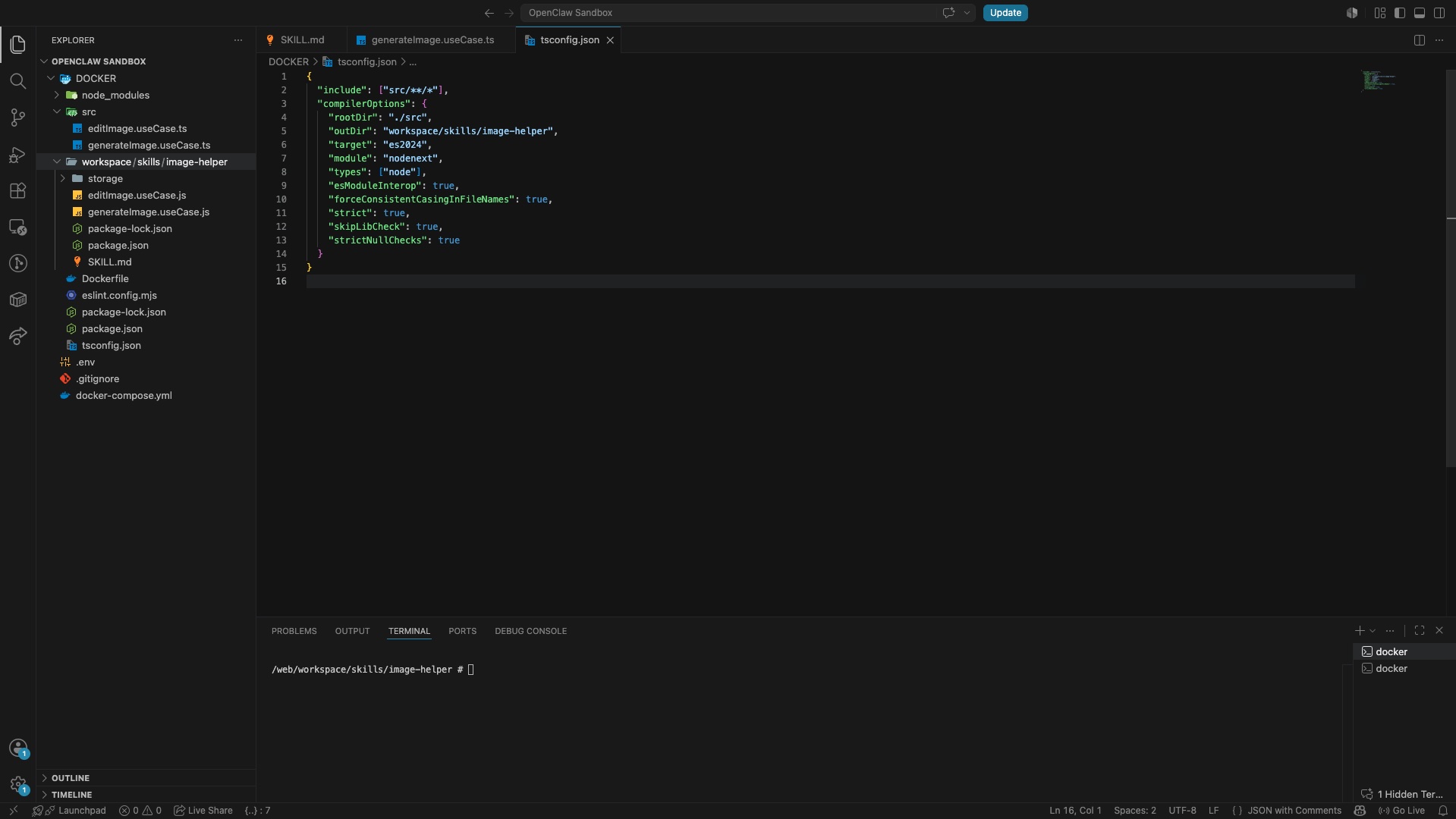
Также наши настройки для TypeScript и ESLint:
Теперь приступаем к написанию файла generateImage.useCase.ts :
Обратите внимание на process.env.OPENAI_API_KEY. Вам надо получить API ключ от OpenAI вот тут.
Далее, создаем SKILL.md:
Теперь, можно все собрать командой:
tsc --noEmit && ./node_modules/.bin/esbuild src/generateImage.useCase.ts --bundle --platform=node --format=esm --outdir=workspace/skills/image-helper --banner:js="import{createRequire as __cr}from'module';const require=__cr(import.meta.url);"
После этого, у Вас должен появится файл generateImage.useCase.js внутри папки image-helper. Напомним, в ней должно быть: generateImage.useCase.js и SKILL.md.
Всю папку нужно поместить на Вашу VDS (или где там OpenClaw лежит) по адресу: ~/.openclaw/workspace/skills.
И не забудьте положить ENV для OPENAI_API_KEY в корень OpenClaw:
OPENAI_API_KEY=token
Файл .env лежит по пути: ~/.openclaw/.env.
Если файла нет, то создайте его самостоятельно, и не забудьте перезапустить OpenClaw.
Когда все сделаете, можете написать своему агенту о том что у него появился новый SKILL. Он закончит все настройки и можете проверить новый навык.
Конечно, если Вы попросите агента отредактировать существующее фото, то он, скорее всего, не справится. Просто для создания и редактирования используются разные методы в API OpenAI. Поэтому Вам надо сделать ещё один useCase. Как раз по этой причине в начале статьи на скриншоте у автора больше файлов, чем получилось сейчас.
В рамках этой статьи мы заканчивать SKILL не будем, но автор выложил полный вариант навыка на GitHub, он доступен по этой ссылке. Спасибо за внимание, если понравилась статья, подписывайтесь на нашу группу в ВК.
Оставьте комментарий